MAELSTROM in context.png

W&C prediction workflow.png
Methods such as linear regression, the calculation of teleconnections and correlations, principal component analysis, and many more, that can be attributed to “machine learning”, are part of the standard toolbox of scientists working in weather and climate (W&C) science already today. It is therefore not fundamentally new to use machine learning (ML) to improve predictions. However, other ML tools such as deep neural networks, decision trees, and evolutionary methods, that allow to emulate more complex non-linear systems and to extract information from very large datasets, are not used within operational W&C model simulations yet, with very few exceptions.
The new ML tools allow for the representation or interpretation of non-linear systems that are much more complex in comparison to the complexity of ML applications that could be trained a decade ago, or when compared to the complexity of systems that scientists can understand if no ML is used. One reason for this change in ability is the breath-taking pace of developments of the toolbox of methods, and in particular of neural network architectures, with more than 100 new ML papers that are added to the arXiv repository every day. This allows to find customised ML solutions for specific application areas and to increase efficiency in training as well as solution quality.
New ML approaches are tested by scientists for their specific application. However, it is very difficult to compare results for specific ML approaches across different applications in a quantitative way. This makes it necessary for scientists to perform excessive trial-and-error testing during training to find the optimal combination of hyper-parameters (e.g., the number of layers or neurons per layer or different activation functions for deep neural networks).
MAELSTROM will address this problem and adopt a successful approach that is used in other scientific domains for the domain of W&C predictions: To develop easily accessible benchmark datasets that allow to perform a quantitative comparison for results with different ML solutions. This approach is, for example, used in image recognition - see for example the MNIST dataset for the detection of handwritten numbers. MAELSTROM will develop similar benchmark datasets for W&C. This will give ML developments in W&C science a substantial push since it will allow to develop ML solutions that are customised to the needs W&C predictions. However, more than one benchmark dataset is required due to the complexity of the Earth System and W&C models.
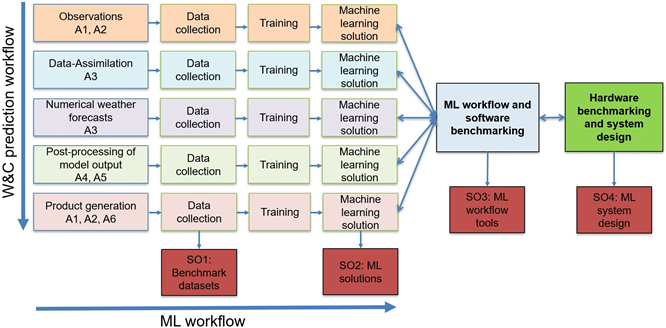
MAELSTROM in the context of the W&C prediction and ML workflows. Illustration of the workflow of W&C models (top to bottom) and how MAELSTROM is covering this workflow with six selected applications (A1-A6). The figure also illustrates the workflow of ML applications from data collection, via training to the development of production-ready ML solution (left to right) which is also covered by the proposal. Experience from the application development will feed directly into the development of workflow tools to optimise the usability of ML applications as well as the W&C modelling framework. The workflow tools will be used to perform a software benchmarking to optimise efficiency of the ML solutions that are developed. The ML solutions that have been developed and improved via the application of ML workflow tools and software benchmarking will be used for hardware benchmarking and the development of compute system designs. The red boxes at the bottom indicate the four main products of MAELSTROM that address the four Specific Objectives 1-4.
The joint expertise of MAELSTROM partners in W&C allows to cover the entire W&C workflow with six selected ML applications A1-A6 that will be studied throughout the co-design cycle, namely:
A1: Blend citizen observations and numerical weather forecasts
A2: Incorporate social media data into the prediction framework
A3: Build neural network emulators to speed-up weather forecast models and data assimilation
A4: Improve ensemble predictions in forecast post-processing
A5: Improve local weather predictions in forecast post-processing
A6: Provide bespoke weather forecasts to support energy production in Europe
MAELSTROM will develop benchmark datasets for the six ML applications
For each of the applications, benchmark datasets will be developed that will consist of terabytes of training data for ML problems that have the potential to be used as large-scale HPC applications. This will offer ML experts the chance to make performance tests for training and inference of ML solutions that were motivated around the high-impact application domain of W&C. MAELSTROM will therefore develop benchmark datasets that will give the use of exascale for ML applications in a physical application domain a significant push. The benchmark datasets will also cover social media and IoT data raised via citizen engagement to enhance the number of observations that are used in conventional W&C predictions.
The datasets will be made available to the community and will be tiered in terms of data size (from gigabytes to tens of terabytes). The benchmark data sets will be published alongside with a justification and explanation of the application, a description of input and output fields, a prototype solution for standard ML tools, and a cost function that should be trained for to allow ML experts with no domain knowledge to use the datasets.
MAELSTROM will develop production-ready ML solutions that are optimised for efficiency, scalability, and quality for six selected ML applications
The solutions will serve as benchmark solutions for the six benchmark datasets. The ML solutions will be published as papers and source code to enable other research groups to use the ML architectures as vanilla solution for their applications. The tools will include deep neural networks that train from three-dimensional, global fields of the atmosphere and will be able to make efficient use of exascale supercomputers for both training and inference as they become available.
The benchmark solutions will serve as blueprints for a large number of ML applications by external research groups in the future. The networks will also be distributed as pre-trained networks as this has proven to be useful in other scientific domains to reduce the number of training cycles. The solutions will be developed in close collaboration between the different MAELSTROM applications to learn from success stories and failures regarding tests of different ML approaches and to tackle the challenges that are named above in a joint effort. To develop ML solutions at the scale of modern supercomputers will make improvements possible that have not been possible when using conventional tools or no supercomputing capacity. To find solutions for the challenges named above will have impact on many ML application domains beyond W&C.
