
Empowering weather and climate forecast
pip install climetlab-maelstrom-radiationOnce installed, shell commands to run each of the experiments can be found in the Table 6 below. Note that the first time one of the experiments is run a data download will occur. With a good internet connection this will take ~3 hours and require ~400Gb of disk space. To run the code with a minimal data download (~3Gb), use
--tier 1below, while noting that the model performance will be dramatically reduced. Details on the location of the data have been documented.
radiation-benchmarks-sw --epochs 50 --batch 512 --model cnn --tier 2 radiation-benchmarks-sw --epochs 50 --batch 512 --model rnn --tier 2 radiation-benchmarks-sw --epochs 50 --batch 512 --model cnn --tier 2 --attention --notf32

The inputs are profiles of atmospheric state and composition, e.g. temperature and aerosol properties. The inputs either live on model levels (137 levels in the IFS model which is used for the study), model half-levels (138 levels), model interfaces (136 levels) or as scalars. A complete list of the variables can be found in deliverable 1.1 or in the CliMetLab plugin. The CliMetLab provides the inputs gathered by level type, such that 3 input arrays are provided, containing the half-level, full-level & surface variables.
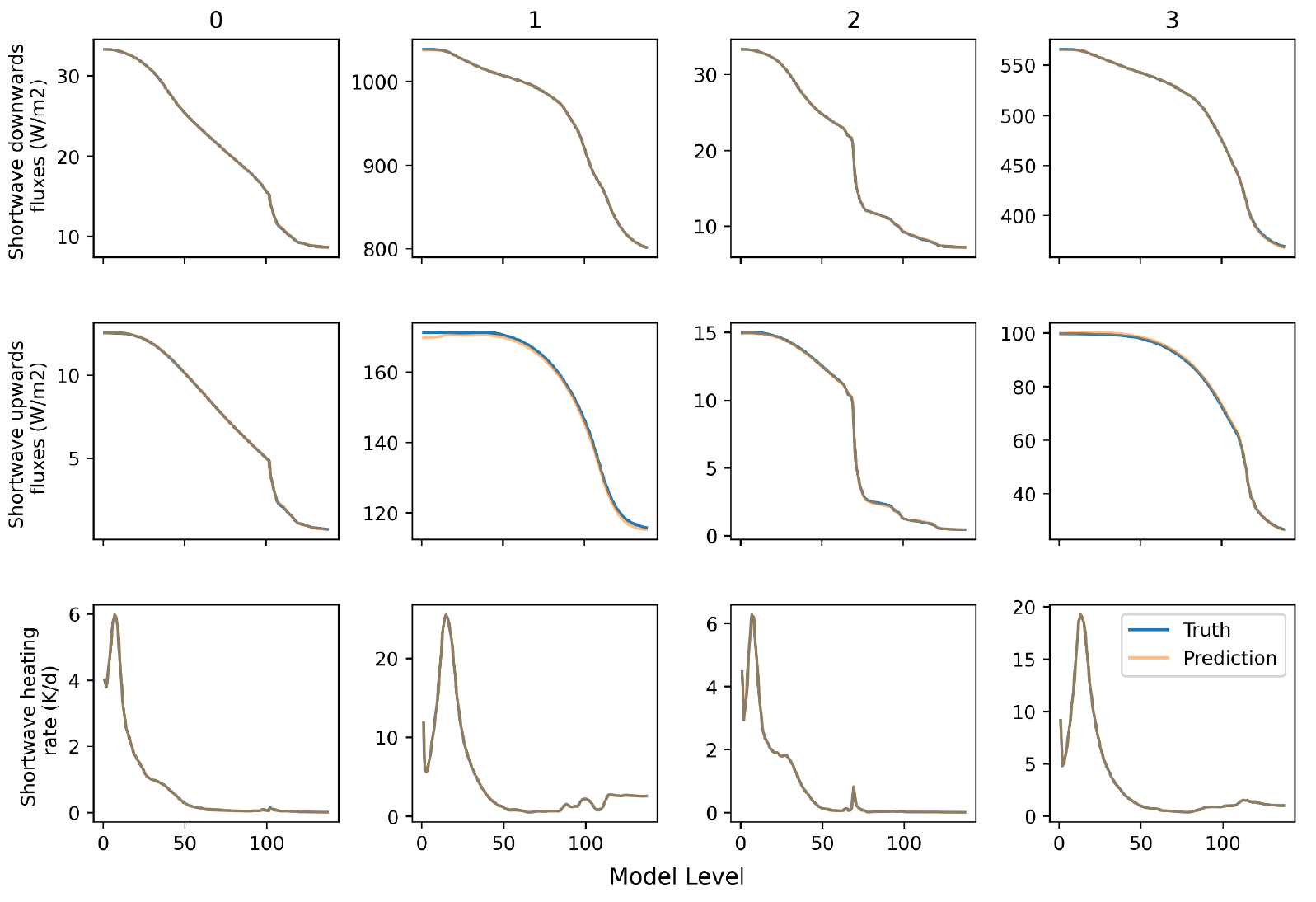
For the outputs, there is a duality between down and up fluxes, the typical output of a conventional scheme, and heating rates. At the surface, fluxes are necessary to heat and cool the surface, in the atmosphere, the heating rates are the desired variable that is used to increment temperature profiles. The two variables are related through
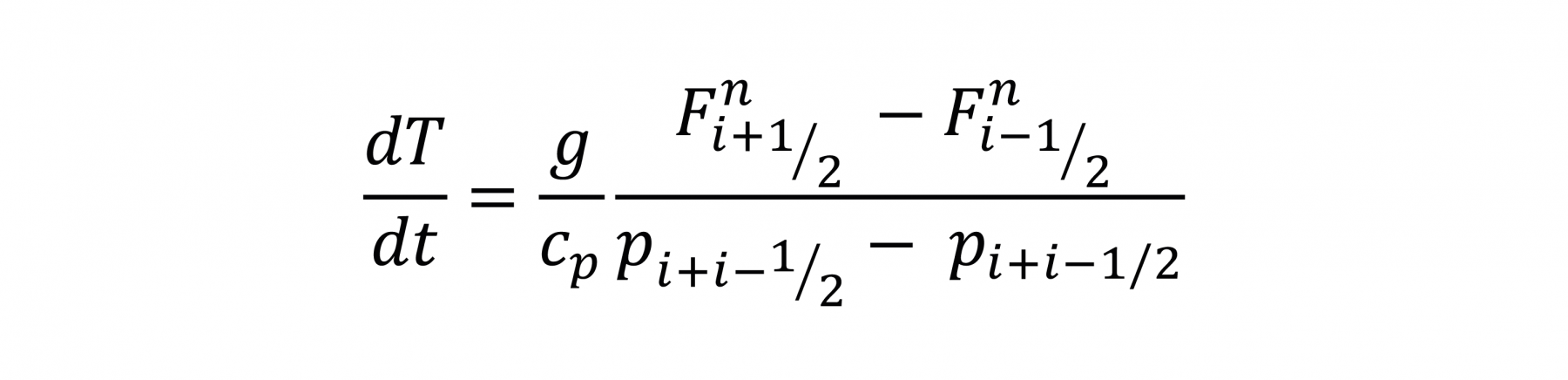
where the left-hand side denotes the heating rate, Fn denotes the net (down minus up) flux, p the pressure, g is the gravitational constant, cp is the specific heat at constant pressure of moist air and i is the vertical index. We will throughout the experiment encode this relationship in a neural network layer and dually learn to minimise errors of the heating rate and flux profiles. Our metrics of interest are therefore the RMSE and MAE of the fluxes and heating rates.
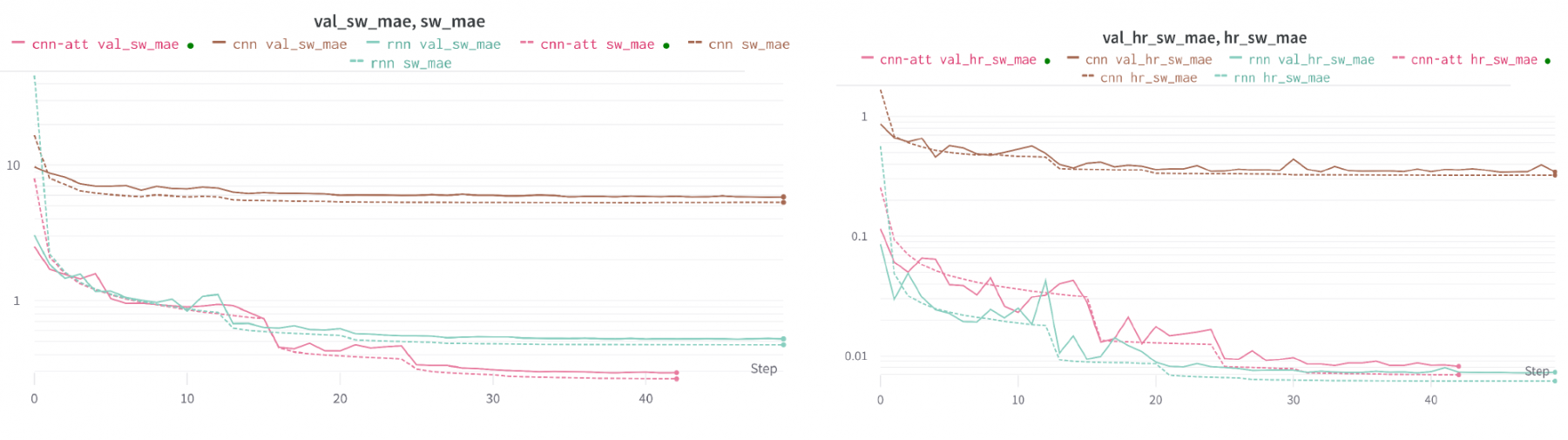
For this phase of reporting, we introduce an extended version of the dataset. This extends the number of example columns used to train the models for learning the radiative transfer process. These can be accessed from the maelstrom-radiation-tf CliMetLab dataset using the subset = “tier-2” argument. This generates a dataset with 21,640,960 examples. This is to be contrasted with the Tier 1 dataset which contained only 67,840 examples. We also introduce Tier 2 subsets for validation and testing, accessible with “tier-2-val” and “tier-2-test”. Each of these contain 407,040 columns from 2019 (training data are taken from 2020). This dataset requires ~400Gb of disk space, a significant amount. We therefore also introduce Tier 3 datasets, which are equivalent for the validation & test splits, but contain “only” 2,984,960 columns, consuming ~60Gb of disk space. We found significant model improvements when using the Tier 2 dataset over the Tier 3 dataset, even when controlling for the number of iterations. Here, we will only present results on the Tier 2 data.
For brevity, we focus our reporting on the shortwave heating process. Equivalent models are being trained for longwave heating, with the current leading architecture proving to be optimal for both wavelengths.
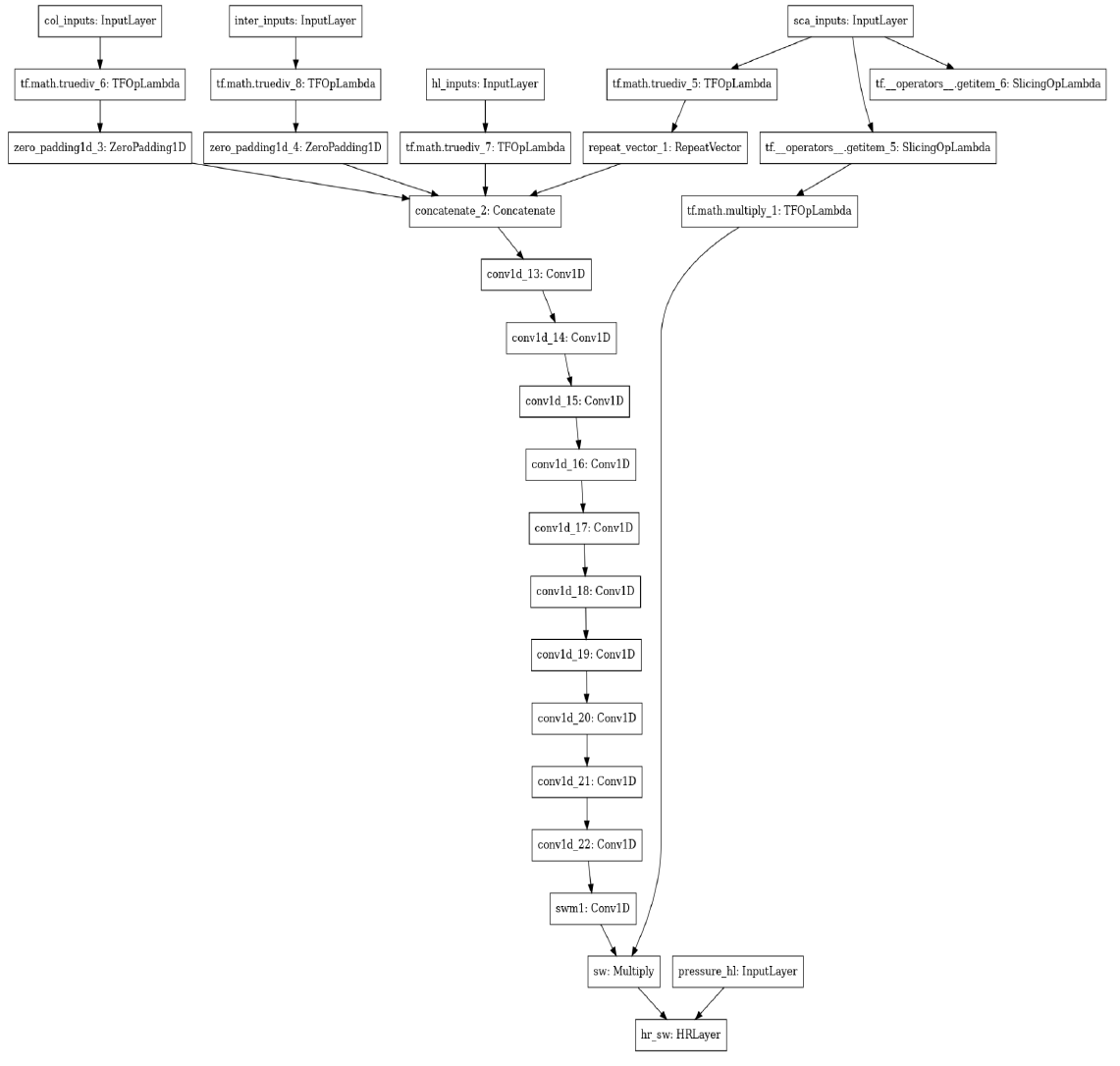
The first network we consider features a convolutional structure. Before this can be applied, the input shapes need to be standardised. Surface variables are repeated 138 times to match the 138 half-levels. Full-level fields are zero-padded at the top of the atmosphere by 1 to match 138. Interface fields are zero-padded at both the top & bottom to match 138. All inputs are concatenated along the channel dimension, resulting in 47 input channels. The learnt component of this model consists of convolutional layers, each with 64 filters, a kernel width of 5 and the Swish nonlinearity (Ramachandran, 2017). First, we use 5 convolutional layers featuring dilated convolutions (Chen et al.,2017), with dilation factors [1,2,4,8,16]. These are used to propagate information throughout the vertical column. Following these we use 5 more convolutional layers without dilation. The next step is to include a final convolutional layer with 2 channels, representing the downwards and upwards fluxes, with a sigmoid activation. This output is multiplied by two scalars, the global incoming solar radiation and the cosine solar zenith angle. This scales the output in proportion to the local incoming flux and provides our output fluxes. Finally, we use a custom layer to enact the heating rate equation outlined in 3.3.1. This takes the fluxes and half-level pressure as inputs. The graph of this model is depicted below.
| Experiment # | Loss | SW MSE | SW MAE | SW HR MSE | SW HR MAE |
|---|---|---|---|---|---|
| 1 | 0.0299 | 1627 | 12.2600 | 0.0963 | 0.0763 |
| 2 | 0.0017 | 1.6180 | 0.4290 | 0.0004 | 0.0061 |
| 3 | 0.0014 | 0.5000 | 0.2498 | 0.0005 | 0.0070 |
The final test of any model for this application is coupling it into the IFS atmospheric model to assess forecast quality. This step will be carried out next to differentiate between the two models. The relative inference costs will also be an important factor if the scientific quality of the forecasts are comparable for both models. A method for introducing these models into the Fortran codebase has been developed4. but this has not yet been tested using GPUs for the inference.
Further model optimisation is surely possible, as some of the hyperparameters in the above models have not been fully explored.
These and other architectures will be examined for the longwave aspect of the heating problem.
Finally, the models for this application will have further value, providing differentiable models for data assimilation. Over the next year we will establish the best methodology for generating the tangent linear versions of our models, and then testing their stability within data assimilation.