Platform for HPC-based machine learning
This application is being delivered by
4cast.
Concept
In MAELSTROM, we aim to develop a web platform that simplifies the workflow of W&C researchers. The platform has various targets that support the development cycle of machine learning applications:
- It should especially be designed for development of W&C applications on HPC infrastructures by providing a unified access to the hardware systems. Here, unified access means that we want to abstract away the infrastructure and specific conditions of the respective computation sites to avoid the requirement of in-depth knowledge for interaction with the specialised software of each site, which typically results in a large overhead of work for researchers.
- A main target is to achieve maximum reproducibility of machine learning solutions. The platform should hence govern all parts of a machine learning workflow: data, application code, experiments (input parameters and output metrics), and models. This allows researchers to review earlier solutions and reproduce them at any time.
- Hosting a large number of machine learning applications and gathering all kinds of information about them enables a detailed evaluation of the machine learning solutions. This allows the software frameworks to provide suggestions for well-performing machine learning solutions to other platform users when approaching new problems:
○ What data have people used for this problem?
○ Which machine learning algorithms, architectures, and input parameters have they applied?
○ How well have these approaches performed, and which have performed best?
This gives newcomers the opportunity to directly jump into the state-of-the-art solutions of a
problem they are interested in and try improving it.
- We want to encourage collaboration within the community to improve the quality of research and enable scientists to benefit from each other’s domain knowledge on specific applications. Platform users should be able to share their machine learning applications with researchers of their choice or the public to encourage knowledge exchange and improve the machine learning solutions.
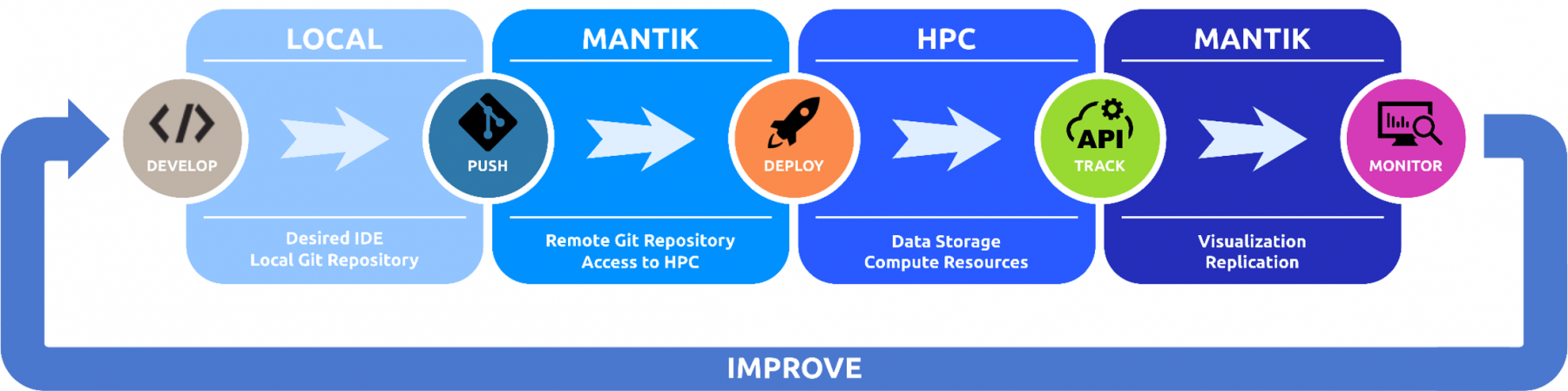
Mantik workflow
Approach
To address these requirements, the following was done:
- We chose to utilise the Open Source machine learning framework MLflow1 for experiment
tracking and model versioning. The software provides a large range of functionality to
support the workflow of machine learning developers.
- For the usage of MLflow, we have developed a cloud architecture on the Amazon Web
Services platform that encapsulates a MLflow Tracking Server and the MLflow GUI2. Natively,
MLflow does not provide any security measures to host these software components publicly
with restricted access. Thus, on top of MLflow, we implemented services that allow for user
management and restrict the access to only allow authorised users to access the cloud
instance.
- To provide users with a unified access to HPC resources, we have developed the Mantik
Compute Backend. It exposes a REST API to submit machine learning applications directly to
a computation site. To allow this, the applications have to conform with the structure of
so-called MLprojects. This format is a feature of MLflow and makes machine learning
applications independent from any hardware or software environments, and thus, makes it
possible to execute them on any system.
- We have developed the Mantik Python package3 – that also comes with a command line interface (CLI) – to provide users with an API that exhibits different functionalities.
○ To give MLflow users access to the cloud instance, the package is able to authenticate users at the platform and give them access to the secured MLflow services from Python applications.
○ The package provides Pythonic access to the Compute Backend API, and hence, enables users to directly execute and supervise their machine learning applications on the desired HPC system from anywhere.
The usage of the package is documented on GitHub.4
- Currently, the Mantik web platform, which integrates all requirements listed above, is under development.
○ For experiment tracking, the platform will support MLflow. The long-term plan is to completely embed the MLflow GUI in Mantik and encapsulate all MLflow features in Mantik.
○ For projects that conform with the MLproject conventions, users will be able to execute their machine learning applications on the HPC system of their choice directly from the browser. The results of their runs will be logged in real-time and directly displayed on the platform.
- The newly developed Deep500 benchmarking tools additionally support logging measured
performance data to Mantik’s MLflow instance.
Python and command line interface
We built user interfaces that allow machine learning developers to:
- Develop all steps of their machine learning applications on a single platform.
- Benchmark the usage of different state-of-the-art machine learning libraries for their specific use case.
- Get unified access to any HPC hardware and infrastructure.
Currently, the Mantik Python API and CLI provide programmatic access to the Mantik API. API provides features for experiment tracking and model versioning:
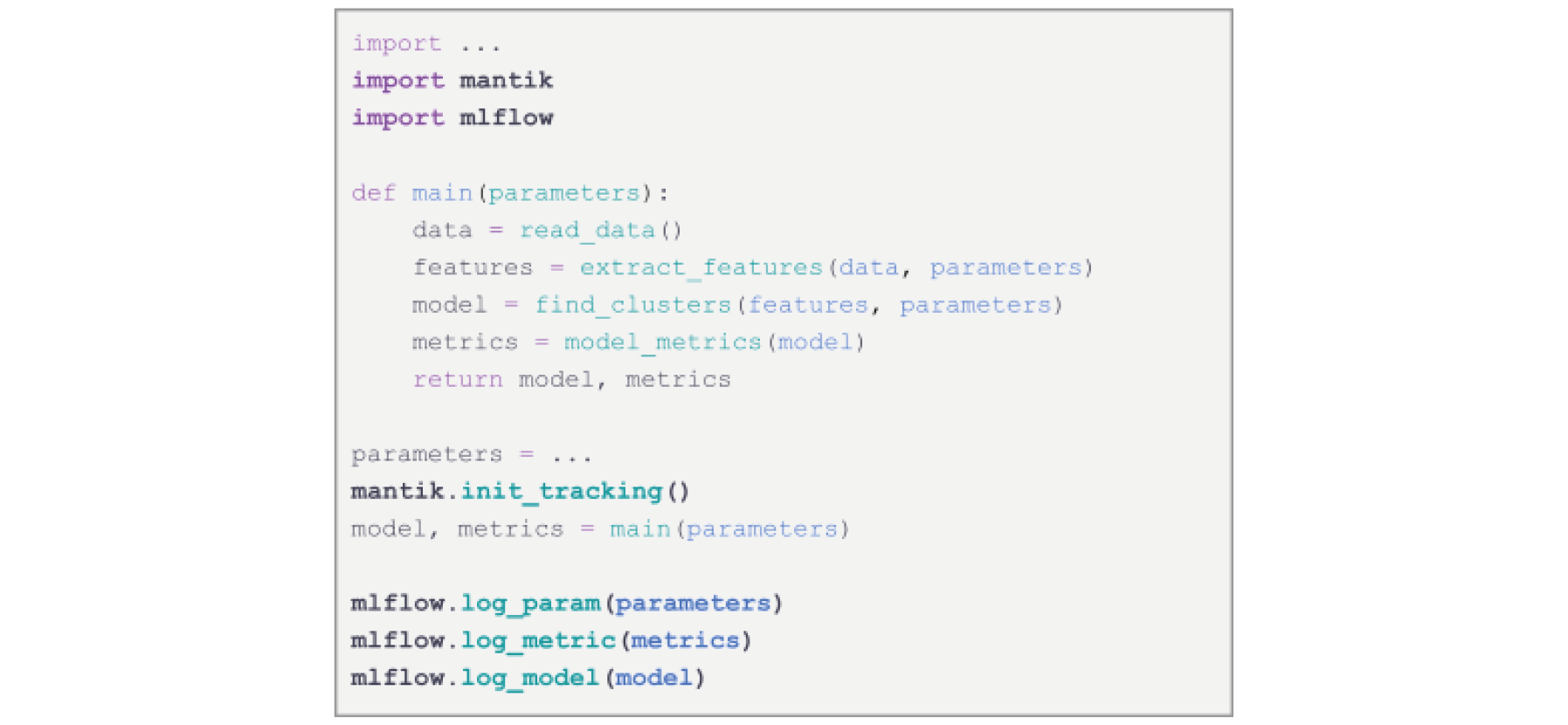
Usage of MLflow with the Mantik Python API. The Mantik package allows authentication at the
secured MLflow cloud instance and logging any desired information.
The API also provides features for remote execution and supervision of applications on HPC hardware:

Execution of an application with the Mantik Compute Backend using the Mantik CLI. The required
YAML config allows configuring the resources that will be requested for the run (e.g. type and number of
compute nodes, CPUs and RAM per node, etc.), as well as defining any required software modules that should
be loaded in the run’s environment.
The example above shows how a user can start the training of a machine learning model on an HPC resource from their local machine. Mantik offers additional commands that allows the user to monitor and interact with a submitted job (or run):
list — shows a detailed list of all submitted runs.
cancel — cancel a submitted run.
status — shows a run's current status (e.g. if the job is queued, running, failed, or successful).
info — shows detailed information about an individual run.
logs — prints the application logs (i.e. stdout/stderr).
download — allows a single file or an entire folder from the run's working directory to be downloaded.
Graphic user interface
In the near future, the GUI, i.e., the Mantik web platform, will provide a more abstract and visual access to the Mantik API.
A preliminary GUI is the MLflow cloud instance that gives access to stored machine learning experiments and models (below). This GUI also offers more advantageous features that allow for a visualisation and comparison of a set of experiments such that researchers can quickly gain insight into the results of their recently executed HPC applications.
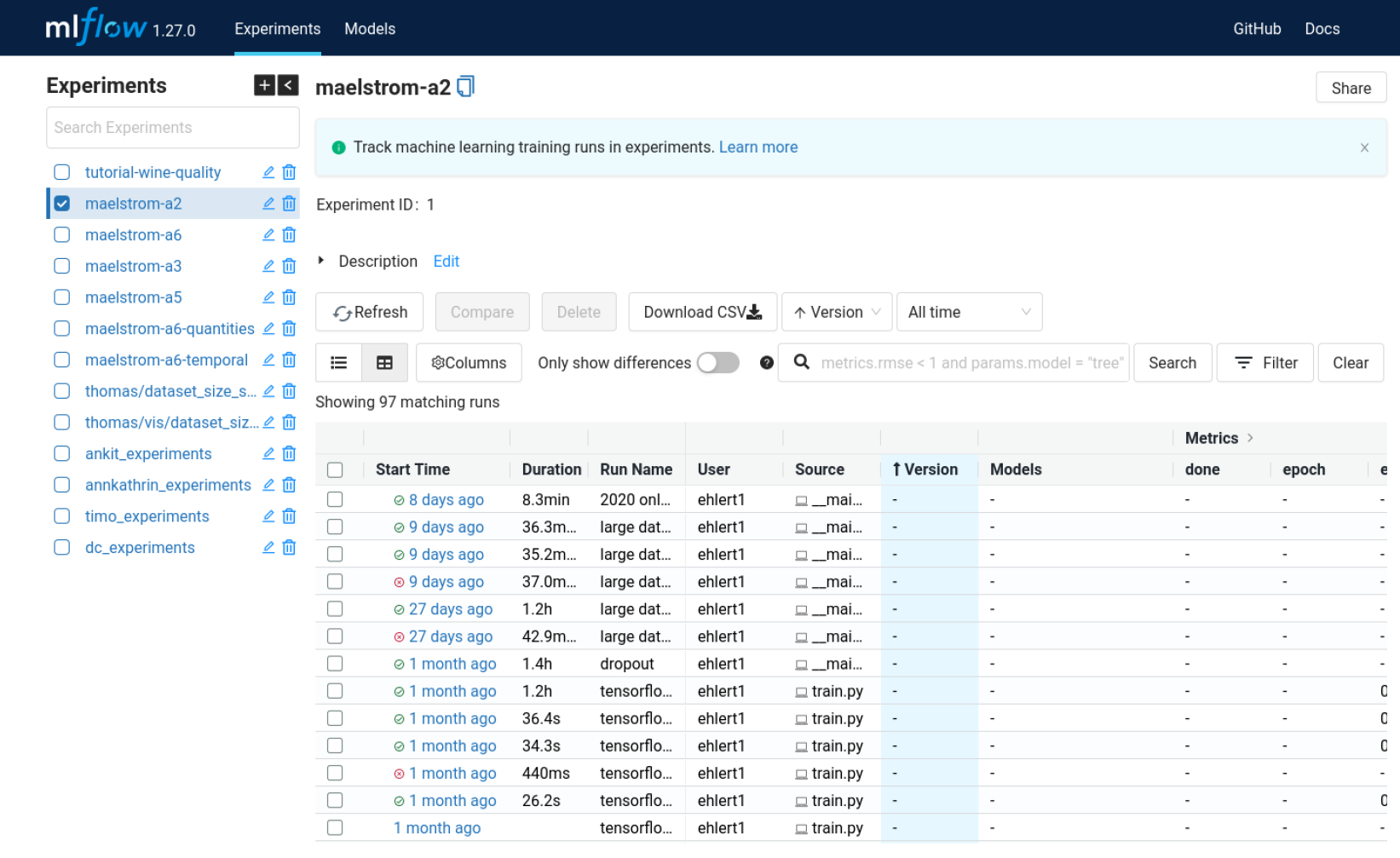
Secured MLflow GUI. It shows all experiments and experiment runs of the users. A run represents e.g.
a model training with specific input parameters and output metrics and a trained model.
The GUI of the Mantik web platform is currently under development (
https://github.com/mantik-ai/mantik-gui). A first version of the platform will enable users to create machine learning projects that manage their data, code, experiments, stored (versioned) models, and allow model training and inference (prediction) on HPC systems. These projects can be shared with other users of the platform (including specific groups of users) to promote knowledge exchange that improves the machine learning solutions. The current layout of the project landing page looks as follows:

Landing page of the Mantik web platform.
Here, users can log in or register (central right button or top right corner buttons), but also just try out the basic features without requiring an account (central left button).
The user’s projects as well as public and shared projects hosted on the platform can be viewed and filtered by different criteria (see Figure 5) such as Name, Author, and Problem Type (e.g. Classification, Regression, Recurrent Neural Network, Natural Language Processing).
Once a project has been selected, the project overview and all other details can be viewed. This view provides all required information about the project:
- Overview (e.g. description, motivation, methodology, latest results, etc.)
- Code repositories (GitHub, Gitlab, or Atlassian Bitbucket ) containing the machine learning application code
- Data (description and access)
- Models – Training (remote training on HPC), Prediction (remote prediction on HPC), Stored (versioned) models.
- Runs (individual runs of training or prediction with models on HPC)
- Experiments (input parameters, metrics, trained models, files, plots, etc.)
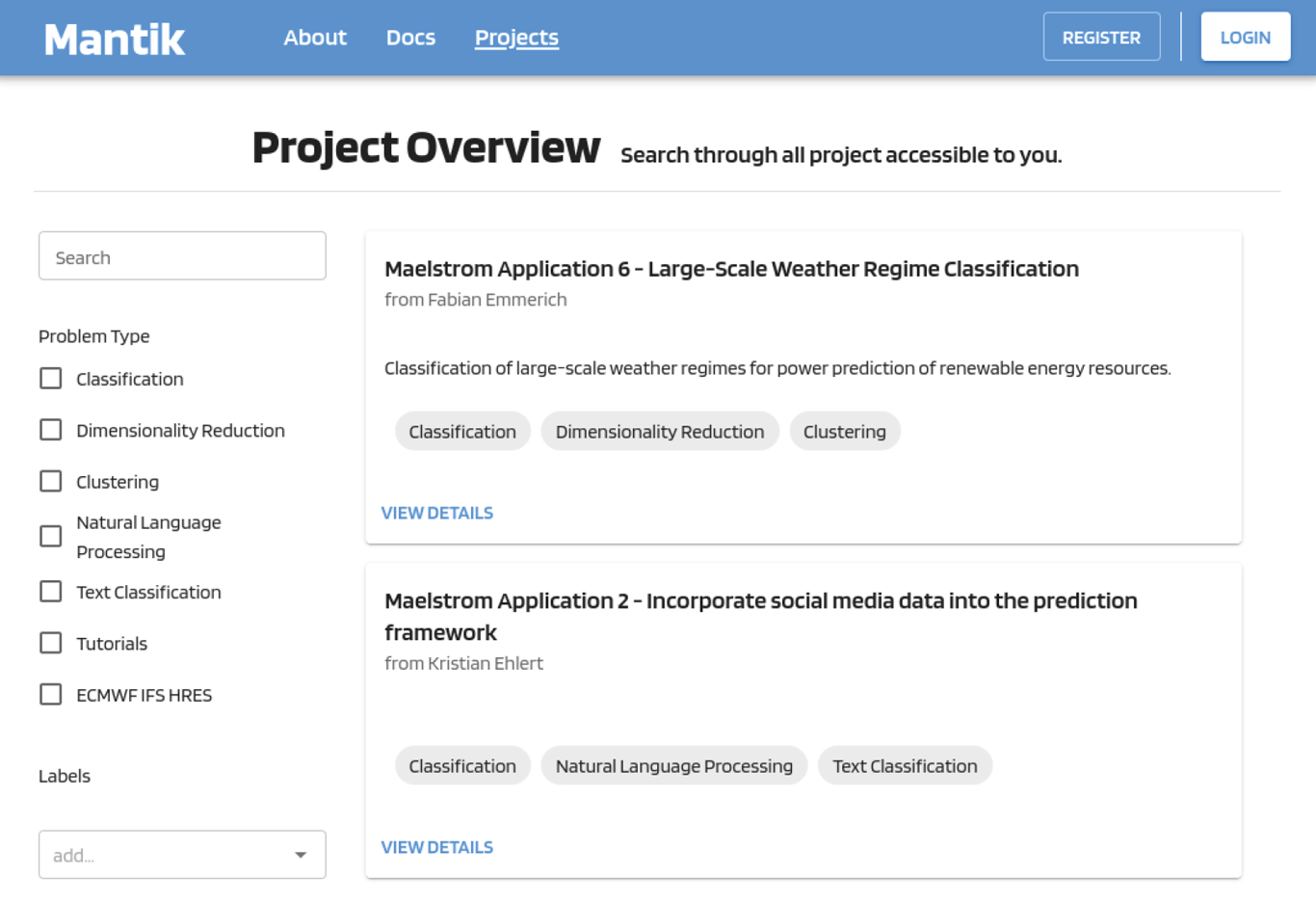
Overview of projects hosted on the platform. Projects can be filtered by applying different criteria.
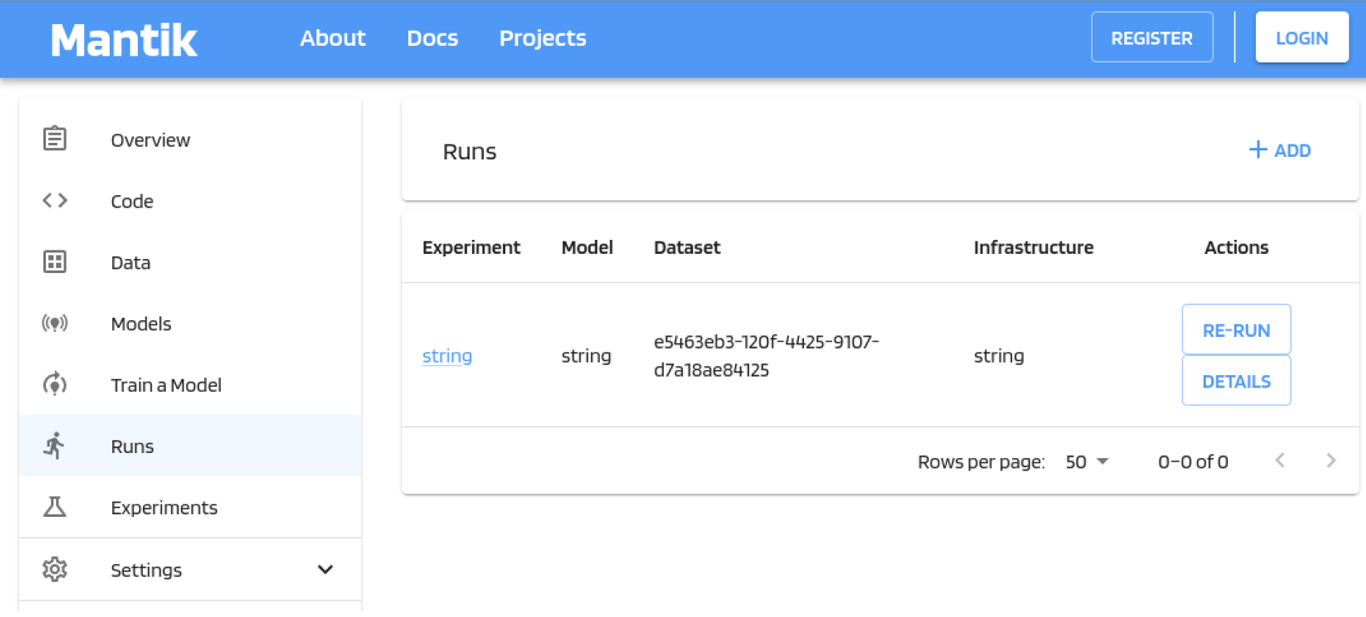
View of a project. Here, we see all runs of the application executed on external infrastructure. Other
project details that can be viewed are listed in the menu bar on the left hand side.

